Unstructured Data v/s Structured Relational Data
Data is a set of values and facts of quantitative and qualitative variables. Data as a general concept refers to the fact that some existing information or knowledge is represented or coded in some form suitable for better usage or processing. Data is measured, collected and reported, and analyzed, whereupon it can be visualized using graphs or images. Data in its raw form is always irrelevant and does not make any sense to the person reading it. To make it more readable or rather usable, data needs to be structured. It is important to understand the difference between structured and unstructured relational data.
Structured Data
Structured Data refers to information with a high degree of organization, that is, data that is stored in an organized manner. It resides in a fixed field within a record or file. Normally data that is stored in relational databases or on spreadsheets in an orderly row and column format forms structured data. In order to store structured data, one must create a data model that specifies the business data that one has to deal with along with the data types such as numeric, alphanumeric, Boolean, etc., data constraints such as primary, referential integrity, check, not null, etc. and metadata information. Because it is well ordered, structured data can be easily entered, stored, queried and analyzed. SQL is most commonly used to manage structured data. SQL helps us perform several operations to analyze the data and fetch desired results. These operations include search, insert, update, delete and others.
Unstructured Data
As the name suggests, unstructured data refers to data that is unorganized and is unable to dwell inside a database or on a spreadsheet. They are difficult to be process and generate reports. Unstructured data comprises of text and multimedia content. A few examples are videos, photos, audio files, presentations and many other kinds of business documents. We know that the business documents follow a structured approach, but their content is unable to fit in a database and so they are categorized as unstructured data. Business Documents within an organization are unstructured data that contain a large amount of useful information that are important in strategic decision-making. It is important to gain valuable insights into this data and hence organizations are now inclined to various technologies such as Hadoop, Data Mining tools, Business Intelligence software and many other technological solutions. The term Big Data is closely associated with unstructured data. Big data refers to extremely large datasets that are difficult to analyze with traditional tools. Although Big Data can include both structured and unstructured data, research show that 90 percent of big data is unstructured data.

The following table shows also shows the differences between structured and unstructured data:

Experts estimate that 80%-90% of the data in any organization is unstructured. And the amount of unstructured data in enterprises is growing significantly, often many times faster than structured databases are growing. The figure below shows the growth of unstructured data as compared to that of structured data:


Types of Data
Spatial Data: Spatial data is the information that has several dimensions. Data that gives importance to location or position with respect to some entity is spatial in nature. For example, maps or images taken from space, remote sensing data, coordinates of a place etc.
Redundant Data: This kind of data refers to duplication of data. It means that the same information is replicated at multiple areas. Such data may be the cause of inefficiencies within a system.
Integrated Operational Data: This type of data is a result of organization’s daily business activities. It is an easily changing collection of data. An integrated operational data store is a subject-oriented, integrated, volatile, current-valued, detailed-only collection of data.
Legacy Data: Legacy data pertains to data from disparate sources, which are old and outdated but still in use because they form the basis of an organization. E.g., XML data, hierarchical & network data, objects, etc.
Fore Data: Fore data are used for describing data architecture’s objects and events. Their primary purpose is presentation only. They are basically the upfront data.
Demographic Data: This data deals with information about the human population such as size, structure, distribution, and spatial and temporal changes.
Integrated Historical Data: This data forms part of the enterprise data that passes through the process of ETL (Extract, Transform and Load). It is stored in a data warehouse and is static in nature. Data in a data warehouse is subject-oriented, non-volatile, integrated and time-variant. This data is also historical and serves the key purpose of statistical analysis. It provides insights to various trends of an organizations relating to revenue, sales among others. An operational database fails to deliver such results. A few key characteristics of data warehouse that facilitate statistical analysis are:
• Denormalization of data that simplifies and improves the query performance• No frequent updates makes it performance relaxed
• Eases consolidation of data from different sources
• Use of historical data in studying trends and patterns
The following figures show the non-volatile nature of Data Warehouse:

Other classification of type of data used today are digital assets, business records, email messaging, specialized web data etc.
Data Warehousing
Data warehouse is a system used for reporting and data analysis. They are central repositories of integrated data from one or more disparate sources and store current and historical data and are used for creating analytical reports for knowledge workers throughout the enterprise. The following video gives an overview about Data Warehousing.
Limitations of Data Warehousing in terms of Data Analysis
The main limitations are as follows:
Inconsistent Data: While loading data, care should be taken to see that the data is consistent or else it might result in performance degradation.
Time Taking: It might take long to extract, transform and load the historical data and hence, the time to develop the data warehouse would also significantly increase.
High Maintenance: These are high maintenance systems. Also they have high initial cost. Any change in the business process or the source system that results in a change in the data warehouse, it would result in very high maintenance costs.
Integration Complexity: Integration of data from various sources is a highly complex. Also, since different tools perform different tasks within a data warehouse, integrating them also increases the complexity of implementing a data warehouse.
Important Data not Captured: In some cases, important information related to the business process under analysis is not captured. These may be important for strategic decision making.
Others: Data owners lose control over the data which in turn raises security and privacy issues. Adding a new data source takes a lot of time. Typically the data is static, limited drill-down capabilities are also few limitations.
Future of Data Warehousing
For a successful implementation of data warehouse for any particular business, it takes years. Any integration requires a lot of effort to ensure consistency. As a result, in the future, an agile model of data warehouse is expected. This model would no longer increase the implementation speed and would facilitate discovery-based analytics. In future, new capabilities could be added to data warehouses so that they handle new types of data. Servers can also be engineered to handle much larger data volumes and workloads. Go as you grow: Just like anything else in enterprise computing, “data warehousing” will fade away as something you don’t have to think or worry about. It will just be there, similar to electricity, enabling amazing things such as finding insights, telling stories, making decisions.
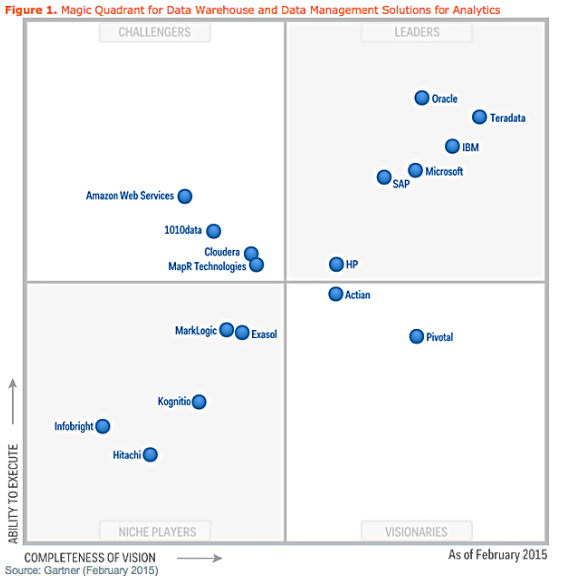
In my opinion cloud-based solutions for data warehousing and analytics might become the standard. The flexibility of the cloud-based solution not only offers performance enhancements but also a native understanding of the wide range of analytic support provided by the data such as Data Services, Big Data and BI Consulting. With cloud based solution the cost of traditional on-premises offerings as well as management overhead costs will be significantly lowered. The following image shows the list of best available Data Warehouse solutions for analytics.
References